Today's challenge was about checking whether the collection of integers forms a valid UTF8 string or not.
The challenge title was "UTF-8 Validation." Let me give you all the question descriptions so you can understand it better. If you need more description about the challenge, you can find more detail here.
Given an integer array data representing the data, return whether it is a valid UTF-8 encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in UTF8 can be from 1 to 4 bytes long, subjected to the following rules:
- For a 1-byte character, the first bit is a
0, followed by its Unicode code. - For an n-bytes character, the first
nbits are all one's, then + 1bit is0, followed byn - 1bytes with the most significant2bits being10.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
x denotes a bit in the binary form of a byte that may be either 0 or 1.
Note: The input is an array of integers. Only the least significant 8 bits of each integer is used to store the data. This means each integer represents only 1 byte of data.
The Solution
I took the simplest approach to solve the challenge, but I believe it can be improved more. What I did was straightforward. Here is the algorithm:
Loop over each element of the list
- Initiate an iterator variable from zero
- Get the element on the iteratorth position of the list
- Convert it to a string representation of its binary code
- Count the number of 1s in front
- Check if all the elements represented by the number of 1s in the first element all start by 10
- If yes, advance to the (iterator + number of 1s)th element and repeat the steps 2 - 5
- If not, return False
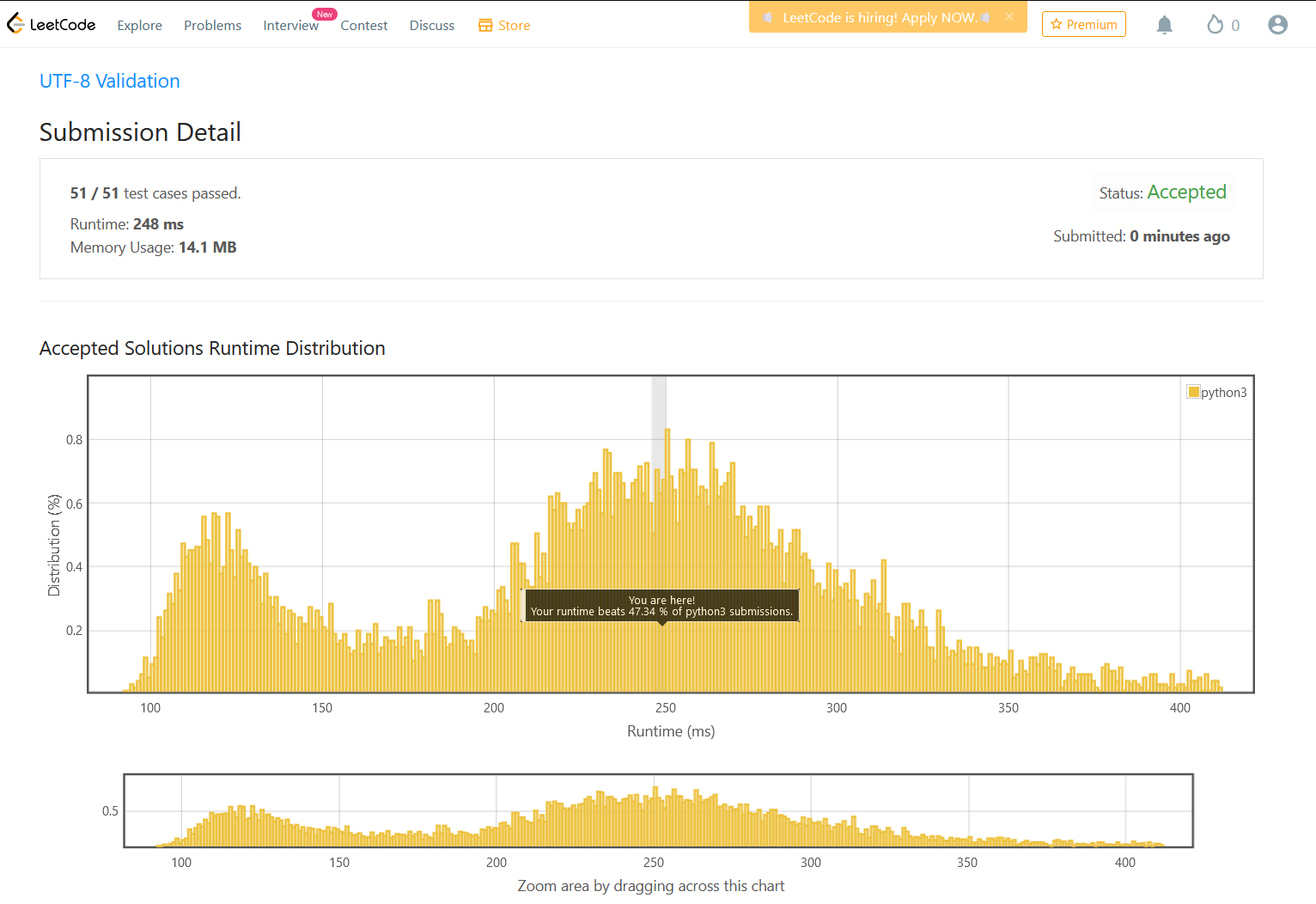
The Result
Runtime: 248 ms, faster than 47.34% of Python3 online submissions for UTF-8 Validation.
Memory Usage: 14.1 MB, less than 71.16% of Python3 online submissions for UTF-8 Validation.